Чтение файла: функция file get content (PHP)
Формально конструкция file get content PHP похожа на file, но помещает прочитанное содержимое в строку, а не в массив строк и позволяет указать смещение в файле, с которого следует начинать чтение.
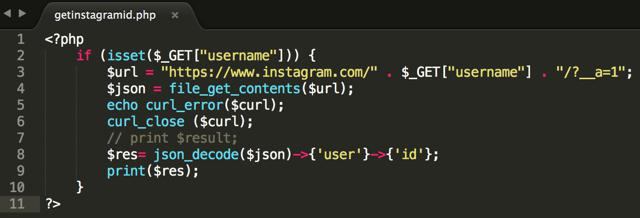
Обычное чтение посредством fopen/fgets/fclose становится менее востребованным. Удобнее прочитать содержимое файла или страницы сайта целиком и потом делать с ним нужные операции. Конструкция file get content PHP позволяет создать более эффективные производительные алгоритмы обработки информации.
Синтаксис и пример использования
Синтаксис:

Здесь $filename - имя файла или URL страницы, $use_include_path - позволяет искать файл в include path, $context - ресурс, созданный конструкцией stream_context_create(), $offset - смещение с которого начинается чтение, $maxlen - максимальное количество данных, которое нужно прочитать.
Обычно используется более простой вариант file get content PHP:
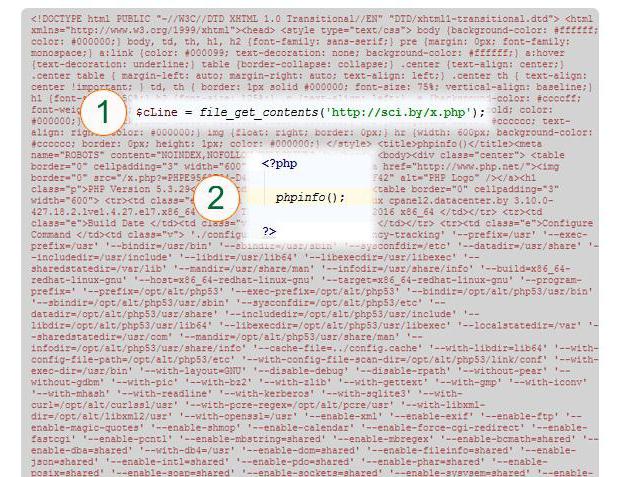
Как видно, результат представляет собой полноценную страницу, в то время как конструкция PHP file get contents по адресу (http ...) прочитала и записала внутреннее содержание этой страницы в переменную $cLine.
Опции и параметры контекста
Следует иметь ввиду, что применение параметра $context открывает большие возможности.

В обычной практике использование всех параметров, кроме $filename, не является популярным правилом. Однако значение, создаваемое конструкцией stream_context_create() и используемое в качестве параметра $context, позволяет писать довольно-таки сложные алгоритмы получения нужной информации.
Различные файловые системы, обработчики потоков (wrappers) требуют различных параметров и опций для описания контекста. Его можно создать посредством конструкций stream_context_create (stream_context_set_option, stream_context_set_params).
Массовая обработка страниц
Вместо конкретного адреса URL параметр $filename может быть представлен именем переменной. Это дает возможность анализировать содержимое сайтов в автоматическом программируемом режиме, узнавать имена страниц, определять ссылки, извлекать нужную информацию.
Можно создать собственный парсер сайтов, поисковую систему и писать программы распределенной обработки информации. Задача актуальная, интересная и практичная.
Чтение текстовых файлов
Проблем нет, какой именно файл читать. В следующем, сложном варианте конструкция file get contents php - пример того, что "вордовский" файл можно прочитать без проблем:

Здесь представлен сложный документ, который используется для тестирования библиотеки PHPOffice/PHPWord. Файл MS Word (*.docx), как известно, представляет собой zip-архив, внутри которого находится информация по стандарту Open XML.
Как правило, файлы документов достаточно большие, сложные, но конструкция file get content PHP справляется с их чтением без затруднений. Специфика именно этого примера состоит в том, что обработка документа чисто средствами библиотеки PHPOffice/PHPWord не позволяет получить необходимые возможности, а последовательное чтение файла попросту невозможно.
В приведенном документе все его элементы (слова, абзацы, формулы, картинки, элементы написания) описываются сериями тегов, причем некоторые могут быть представлены последовательностью вложенных друг в друга объектов.
Если взять пример документа (*.docx) с таблицами, ситуация вовсе не решаема при последовательной обработке файла. Требуется как минимум два прохода по телу документа, если не вдаваться в частности, например, при вложенности таблиц друг в друга.
Проблемы кодировки и спецсимволов
Если чтение сложных файлов не вызывает проблем, то проблемы вызывает работа с простыми файлами. Изначально следует принять за аксиому: конструкция file get content PHP читает правильно. Даже если не использовать те или иные параметры, самый простой вариант ее применения всегда сработает как надо.
Сложности вызывают угловые скобки и кодировка файла. Следует отличать работу внутри алгоритма от отображения результата в окне браузера. На рисунке с примером вордовского файла строка (1) - $cLine = scChangeLTGT($cLine) - вызывает функцию преобразования пары угловых скобок в спецсимволы «<» и «>» иначе просто прочитанный файл не всегда можно отобразить в окне браузера. Как писать эту функцию - не суть важно, но существенно не забывать от том, что прочитанная информация может содержать теги XML и HTML, и это требует особого внимания.
Следующий момент: кодировка файла. Далеко не всегда простой текстовый файл не создает проблем. Если читается текстовая информация, то наличие русских букв может создать определенные трудности (2).
$cLine = iconv('UTF-8', 'CP1251', $cLine). В этом контексте использование функции iconv() с правильным направлением преобразования актуально не только в отношении PHP "file get contents http://" для чтения страницы сайта, но и когда читается обыкновенный локальный файл.
Если результат чтения «не виден», первое дело - проверить кодировку символов.
Похожие статьи
- Запись данных в файл при помощи php file_put_contents.
- Checkbox html: примеры красивых кнопок на чистом CSS, создание "аккордеона", получение значений из форм с помощью PHP и jQuery
- Извлечение координат из файла dxf autocad с помощью функции explode php
- PHP-массив: функции и значение
- Обрезаем строку PHP: простые способы
- Функция file_put_contents в PHP — что это? Описание, примеры
- PHP iconv() - преобразование кодировки символов