Кодировка ASCII. Таблица кодировки ASCII
Под кодированием информации в компьютере понимается процесс ее преобразования в форму, позволяющую организовать более удобную передачу, хранение или автоматическую переработку этих данных. С этой целью используются различные таблицы. Кодировка ASCII — это первая система, разработанная в Соединенных Штатах для работы с англоязычным текстом, которая получила впоследствии распространение во всем мире. Ее описанию, особенностям, свойствам и дальнейшему использованию посвящена статья, представленная ниже.
Отображение и хранение информации в ЭВМ
Символы на мониторе компьютера или того или иного мобильного цифрового гаджета формируются на основе наборов векторных форм всевозможных знаков и кода, позволяющего найти среди них тот символ, который необходимо вставить в нужное место. Он представляет собой последовательностей бит. Таким образом, каждому символу должен однозначно соответствовать набор нулей и единиц, которые стоят в определенном, уникальном порядке.
Как все начиналось
Исторически сложилось так, что первые ЭВМ были англоязычными. Для кодирования символьной информации в них было достаточно использовать всего лишь 7 бит памяти, тогда как для этой цели выделялся 1 байт, состоящий из 8 битов. Количество знаков, понимаемых компьютером в таком случае, было равно 128. В число таких символов входили английский алфавит с его знаками препинания, числа и некоторые специальные символы. Англоязычная семибитная кодировка с соответствующей таблицей (кодовой страницей), разработанная в 1963 году, была названа American Standard Code for Information Interchange. Обычно для ее обозначения использовалась и используется и по сей день аббревиатура «Кодировка ASCII».
Переход к мультиязычности
Со временем компьютеры стали широко использоваться и в неанглоговорящих странах. В связи с этим появилась нужда в кодировках, позволяющих использовать национальные языки. Было решено не изобретать велосипед, и взять за основу ASCII. Таблица кодировки в новой редакции значительно расширилась. Использование 8-го бита позволило переводить на компьютерный язык уже 256 символов.
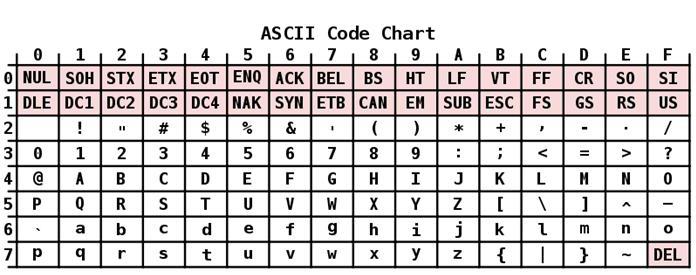
Описание
Кодировка ASCII имеет таблицу, которая делится на 2 части. Общепринятым международным стандартом принято считать лишь ее первую половину. В нее входят:
- Символы с порядковыми номерами от 0 до 31, кодируемые последовательностями от 00000000 до 00011111. Они отведены для управляющих символов, которые руководят процессом вывода текста на экран или принтер, подачей звукового сигнала и т. п.
- Символы с NN в таблице от 32 до 127, кодируемые последовательностями от 00100000 до 01111111 составляют стандартную часть таблицы. В их число входят пробел (N 32), буквы латинского алфавита (строчные и прописные), десятизначные цифры от 0 до 9, знаки препинания, скобки разного начертания и другие символы.
- Символы с порядковыми номерами от 128 до 255, кодируемые последовательностями от 10000000 до 11111111. В их число включены буквы национальных алфавитов, отличные от латинского. Именно эта альтернативная часть таблицы кодировка ASCII используется для преобразования в компьютерную форму русских символов.
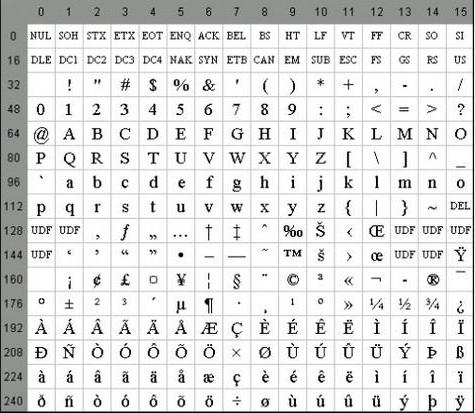
Некоторые свойства
К особенностям кодировки ASCII относится отличие букв «A» - «Z» нижнего и верхнего регистров только одним битом. Это обстоятельство значительно упрощает преобразование регистра, а также его проверку на принадлежность к заданному диапазону значений. Кроме того, все буквы в системае кодировки ASCII представляются собственными порядковыми номерами в алфавите, которые записаны 5 цифрами в двоичной системе счисления, перед которыми для букв нижнего регистра стоит 0112, а верхнего — 0102.
К числу особенностей кодировки ASCII можно причислить и представление 10 цифр - «0»-«9». Во второй системе счисления они начинаются с 00112, а заканчиваются 2-ми значениями чисел. Так, 01012 эквивалентно десятичному числу пять, поэтому символ «5» записывается как 0011 01012. Опираясь на сказанное, можно легко преобразовать двоично-десятичные числа в строку в кодировке ASCII посредством добавления слева битовой последовательности 00112 к каждому полубайту.

"Юникод"
Как известно, для отображения текстов на языках группы юго-восточной Азии требуются тысячи знаков. Такое их количество никак не описывается в одном байте информации, поэтому даже расширенные версии ASCII уже не могли удовлетворять возросшие потребности пользователей из разных стран.
Так, возникла необходимость создания универсальной кодировки текста, разработкой которой при сотрудничестве со многими лидерами мировой IT-индустрии занялся консорциум "Юникод". Его специалистами была создана система UTF 32. В ней для кодирования 1 символа выделялось 32 бита, составляющих 4 байта информации. Главным недостатком было резкое увеличение объема необходимой памяти в целых 4 раза, что влекло за собой множество проблем.
В то же время для большинства стран с официальными языками, относящимися к индоевропейской группе, количество знаков, равное 232, является более чем избыточным.
В результате дальнейшей работы специалистов из консорциума "Юникод" появилась кодировка UTF-16. Она стала тем вариантом преобразования символьной информации, которая устроила всех как по объему требуемой памяти, так и по числу кодируемых символов. Именно поэтому UTF-16 была принята по умолчанию и в ней для одного знака требуется зарезервировать 2 байта.
Даже эта достаточно продвинутая и удачная версия "Юникода" имела некоторые недостатки, и после перехода от расширенной версии ASCII к UTF-16 увеличивала вес документа в два раза.
В связи с этим было решено использовать кодировку переменной длины UTF-8. В таком случае каждый символ исходного текста кодируется последовательностью длиной от 1 до 6 байт.

Связь с American standard code for information interchange
Все знаки латинского алфавита в UTF-8 переменной длины кодируются в 1 байт, как в системе кодировки ASCII.
Особенностью ЮТФ-8 является то, что в случае текста на латинице без использования других символов, даже программы, не понимающие "Юникод", все равно позволят его прочитать. Иными словами, базовая часть кодировки текста ASCII просто переходит в состав новой UTF переменной длины. Кириллические знаки в ЮТФ-8 занимают 2 байта, а, например, грузинские — 3 байта. Созданием UTF-16 и 8 была решена основная проблема создания единого кодового пространства в шрифтах. С тех пор производителям шрифтов остается только заполнять таблицу векторными формами символов текста исходя из своих потребностей.
В различных операционных системах предпочтение отдается различным кодировкам. Чтобы иметь возможность читать и редактировать тексты, набранные в другой кодировке, применяются программы перекодировки русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики и позволяют читать текст вне зависимости от кодировки.

Теперь вы знаете, сколько символов в кодировке ASCII и, как и почему она была разработана. Конечно, сегодня наибольшее распространение в мире получил стандарт "Юникод". Однако нельзя забывать, что он создан на базе ASCII, поэтому следует по достоинству оценивать вклад его разработчиков в сферу IT.
Похожие статьи
- Как определить кодировку? Зачем это нужно?
- Знак "Примерно равно": способы печати на компьютере
- PHP iconv() - преобразование кодировки символов
- Двоичное кодирование информации
- Свободная таблица символов Юникода
- Расширение текстового файла — описание популярного формата
- Что такое кодирование и декодирование информации? Алфавит кодирования